Mailing list membership is a must for anyone who works with complicated computer technology, such as a programming language, a server, or a professional software package. On popular mailing lists for difficult topics, such as Linux distributions, messages stream in at every hour of the day and night.
How many messages on these lists get satisfactory answers? How long does it take to resolve the questions? These are just two of the simpler ways to measure a mailing list's effectiveness (we will encounter others as we proceed).
This article presents the results of a modest research project to measure the effectiveness of two mailing lists, which will be the start of what I hope to be a larger study. The article covers:
It's worth measuring the effectiveness of mailing lists for several reasons. Anyone who runs a project (and anyone who depends on the software for critical functions) should care whether this central resource is working well. But there are more far-reaching issues at stake.
First, mailing lists organize access to information information in a much looser and more fluid manner than formal documentation. Insofar as the lists meet a need, they can provide clues that those writing formal documentation can learn from to reach an audience more effectively.
Second, mailing lists are part of larger phenomenon of grassroots information sharing, as seen in wikis, news blogs, the open Internet-based peer review of scientific articles, social networking sites, and web mash-ups. Many of these are being closely studied by social scientists; for instance, Harvard held a conference on Wikipedia earlier this month. The humble mailing list belongs in the ranks of these social trends. Just consider that it's made up of spontaneous contributions by thousands of people who don't wait for experts to provide information, but generate it themselves and share it in peer-to-peer fashion.
Finally comes the motivation that drove me to do the research in this article. Mailing lists are just one instance (but one that's relatively easy to follow and measure) of what I refer to as community documentation. In the computer field, it is part of an information ecosystem that includes reference material by project developers, web pages, IRC chat rooms, and other places where non-professionals (often on a volunteer basis) try to educate the public.
People increasingly turn to this ecosystem in place of formal documentation created by companies such as O'Reilly Media. Users of this resource will be able to do more with their systems, and find out how to do it with less frustration and wasted time, if its quality improves. I've already made this ecosystem the subject of two major articles: Splitting Books Open: Trends in Traditional and Online Technical Documentation and Rethinking Community Documentation.
The questions I started with while examining mailing lists were:
How many questions get answered?
How long does it take to answer questions (measured both in the number of messages and in the elapsed time)?
How many external resources (books, web sites, and standard documentation such as Unix man and info pages) are referred to?
How much noise—unhelpful or irrelevant messages—do the lists suffer from?
I chose to do this preliminary research on two mailing lists I know well: the Fedora and Ubuntu lists. Fedora and Ubuntu are two of the most popular Linux distributions, but both require a good deal of tinkering if you want to do anything not explicitly built in to each distribution. The lists are very active, and anything is fair game: hardware, drivers, applications ranging from mail clients to enterprise-level servers, and related projects such as the SELinux and AppArmor security systems.
Research on mailing lists is facilitated by the way they organize messages. When people answer a question (or add to another answer) the mail software links all the messages in a set of messages called a thread. A mail client can group messages by thread, so they are easy to segregate from the rest of an active list.
My goal was to track particular threads from the initial message (which asked a question) to the end. To choose the threads, I generated random timestamps ranging over a period of about three weeks, and examined the first message dated after each timestamp. If the thread was started by a technical question requiring help from the list, I read the entire thread and determined where it led. I skipped threads that were not about technical support, such as threads about what would come in the next release of the software, or about how many users the software has. This is because I'm interested in how well mailing lists serve as sources of information that help people use their systems more effectively.
I classified a total of 206 messages on 28 threads. This is not a large sample, but it's enough to show some trends and generate issues for further research. The reading and classification took about five hours.
Threads did not always correspond neatly to conversations. Sometimes a new person would post a new question as part of an existing thread. I ignored this question and any responses, just as if the person had used a different thread. On the other hand, it's possible that someone started a new thread to answer a question I was following, and if so, I would have missed the discussion (but so might the list members following the thread).
With the data in hand, I had to classify each thread as resolved or unresolved. The classification was obvious whenever the person who posted the original question ended the thread, either to thank people for solving the problem or to report that the problem still existed. If the original correspondent did not clearly indicate the status, I usually gave the mailing list the benefit of the doubt: so long as answers seemed on-topic and intelligent, I classified the thread as resolved. In just one case I classified the thread as unresolved, because the answers looked like wild stabs in the dark and did not coalesce into a coherent plan of action.
To judge how much noise was on the list, I also classified messages into the following categories:
This was simply the message that began the thread; the original question.
This category covered slightly over half the messages. A message does not have to lead directly to a solution to be classified as helpful. Often, someone must rule out a possible cause before finding the real cause, just as a doctor must run a test to rule out a serious disease before sending the patient home to take aspirin.
Such diagnostic recommendations are also useful in educating other list members about possible causes of similar problems they encounter on their systems.
A few messages take the readers in the wrong direction and delay resolution. For instance, if a message directs someone to the wrong source for software, I classify it as unhelpful.
This covers a wide range of messages that do not make any attempt to solve a problem. Common messages of this type include "Don't use capital letters" and "Please put your comments at the bottom, not the top, when you quote other messages."
These messages may play a useful role in maintaining the health of the list and facilitating its use. But one can't deny that every minute one spends paging through such messages is a minute that one is not spending on solving the problem. In the larger scheme of things, a list tends to build a community, and provides many benefits along those lines. But this article deliberately focuses on the narrow role of a mailing list as a sustitute for formal documentation; to provide something easy to measure, I have chosen to deal with the list's efficiency at answering technical questions and to leave aside the softer benefits that accrue from reading and posting to the list.
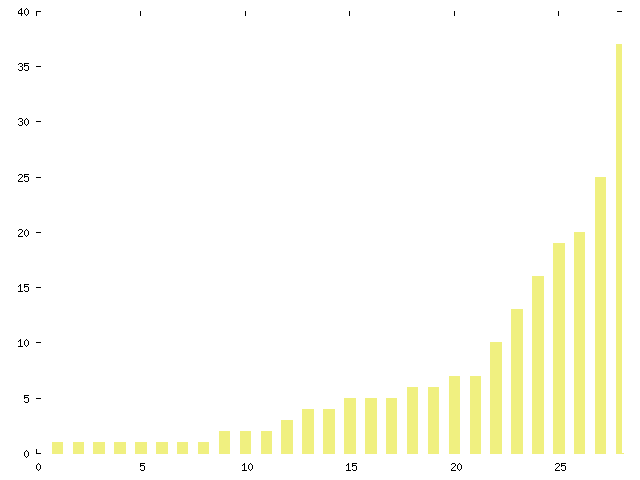
Figure 1 shows the distribution of messages across all 28 threads. The distribution follows a typical power law, with many low-count threads at the left end (8 threads containing only one message, for instance) and a few high-count ones on the right. The high-count threads were almost always created by a high volume of irrelevant messages. Correspondents went off on tangents such as whether a volunteer free-software developer should respond to error reports from users.
Figure 1. Number of messages per thread
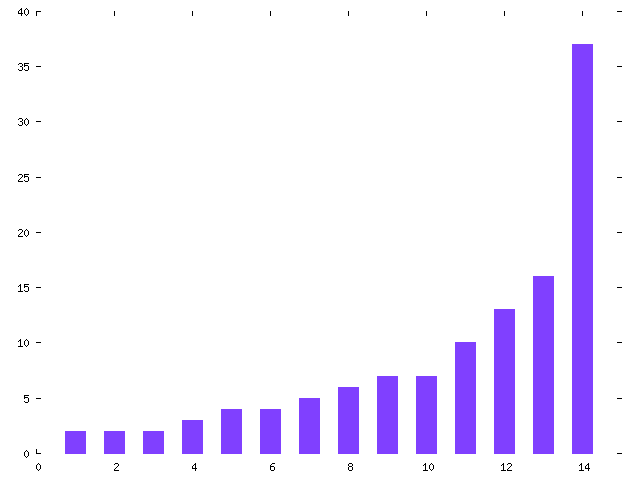
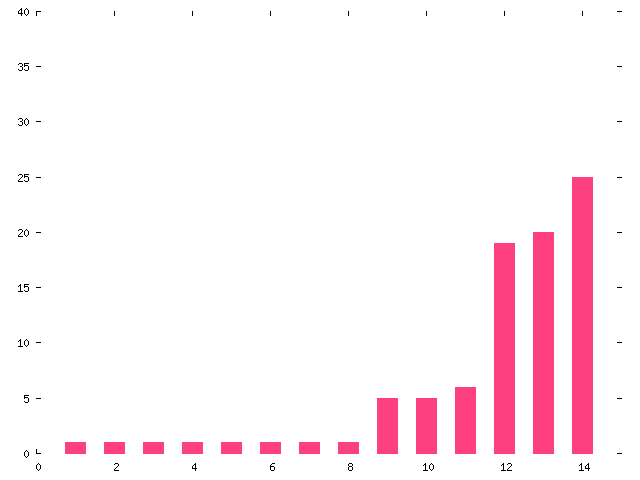
Figures 2 and 3 show a more informative breakdown: the number of messages on resolved threads versus unresolved threads. Once again, threads at the right of each chart are skewed by the preponderance of irrelevant messages.
|
|
|
Figure 2. Number of messages on resolved threads |
Figure 3. Number of messages on unresolved threads |
One interesting result is the similarity between the charts in Figures 2 and 3; the numbers of messages on resolved and unresolved threads are comparable. I expected the volume of messages to be much higher on unresolved threads. This is because I compared the search for answers to a problem to searches in computer software, as well as to real-life searches (such as the unsuccessful search I made in my basement for a hack-saw on the morning I wrote this paper). The worst-case time is always taken by a search that fails.
However, it seems that the mailing lists I examined are efficient. If the list members can solve a problem, they provide the answer quickly. If they can't solve it, they abandon the effort. While this is efficient, it's possible that more threads would be resolved if list members tried harder. This is particularly pertinent because 8 out of the 28 threads had only one message. In other words, nearly one-third of all questions elicited absolutely no response.
One of my colleagues said that members of Linux-related lists used to be more helpful during the early days of Linux, when mere use of the operating system was considered exciting. He sensed that the commercialization of Linux has caused some of the expert users to lose interest in helping new users. But the lists remain quite high-volume. Whatever the cause of the unanswered messages, the results should be checked by further surveys on other mailing lists.
In the conclusion to this article, I'll talk about whether a more exploratory and experimental approach would benefit the users of the list.
This is the fundamental question that determines the value of the list. Coincidentally, the 28 threads in the study were perfectly divided: half were resolved and half were not. Is this result good or bad? It depends on how you look at it.

Optimist or pessimist?
As a member of the lists, I consider the results good enough to encourage people to post questions. The chances of receiving the advice that breaks a logjam are pretty high.
But from a broader standpoint of meeting the needs of the community, the results are not so good. In my sample, half the people who came to the list left without the information they needed.
I'll temper the results by pointing out that topics related to Fedora and Ubuntu are particularly difficult to answer because they're so varied. A mailing list on a programming language or a utility such as a spreadsheet would probably generate a higher percentage of answers.
In the conclusion to this article I'll examine the complicated issues that surround the definition of what information people need.
Figure 4 shows the time it took to resolve each of the 14 resolved threads. If a single message provided the answer, I measured the resolution time from the time the question was posted till the time the first correct answer was posted. The resolution times for a few threads were less clear, because several people contributed ideas and the original correspondent eventually responded that he or she had solved the problem; I took this message as the resolution time. Finally, some threads included multiple responses that seemed valuable, but no resolution was reported; here I considered the thread resolved but took the time of the last helpful response as the resolution time.
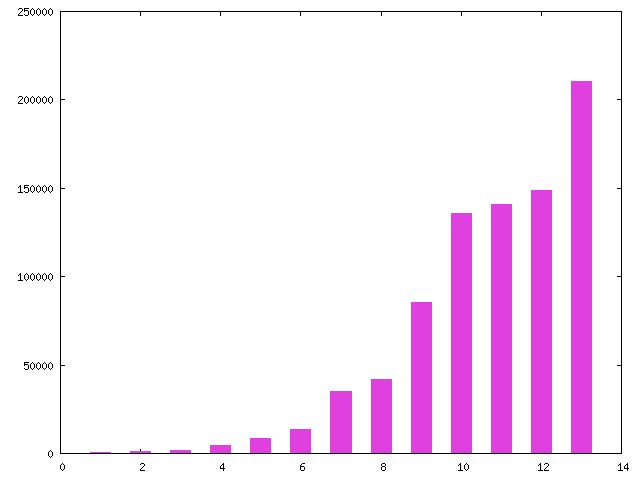
Figure 4. Resolution time
Resolution times varied widely, and results at the high end are probably not very meaningful because I had to guess at many resolutions. The minimum resolution time was 8 minutes, the maximum was 2 days, 10 hours, and the median was 9 hours, 45 minutes. (The median is probably a more accurate average than the mean because the threads with the longest response times may be measured incorrectly for reasons I gave earlier.)
I have heard that resolution time is better on other lists that cover narrower topics. The median in this case is pretty impressive for an interactive forum that spans the world's continents. But if the person posing the question had documentation that answered the question, the answer could probably be found in half an hour or so. Of course, the questioner can perform other tasks in the time it takes to wait for an answer, but conversely, his or her use of the mailing list requires other people to spend time on the problem. So the results here suggest that mailing lists are rather inefficient compared to high-quality documentation.
| Category | Number of messages | Percent of total |
|---|---|---|
| Helpful | 118 | 57 |
| Irrelevant | 54 | 26 |
| New | 28 | 14 |
| Unhelpful | 6 | 3 |
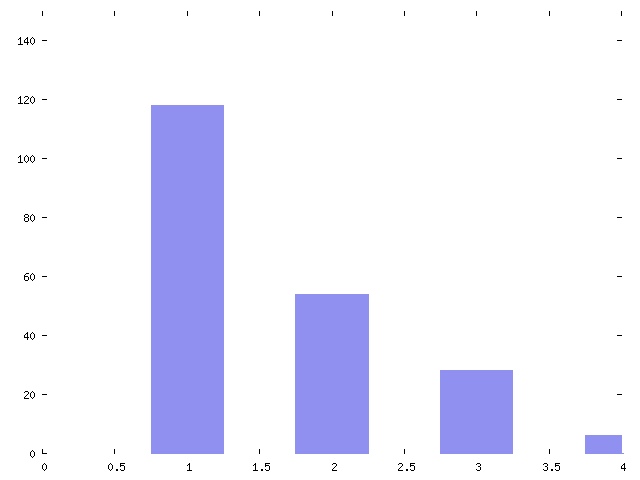
Figure 5. Categorization of messages by helpfulness
The low number of unhelpful messages is encouraging. But the high number of irrelevant messages (even though some irrelevant messages have value for list members in ways that don't directly pertain to solving technical problems) shows that participation in the list has high overhead. And indeed, the volume of irrelevant messages forms a common complaint among users of mailing lists.
Most lists contain off-topic threads, as well long threads about non-technical issues such as upcoming conferences. As I indicated, non-technical messages may be valuable for reasons of their own, and if their subject lines are clear (not always the case) they can be avoided be people who are uninterested in them.
But many technical threads also contain irrelevant messages. As one example, a new user posted a question about hardware and was receiving useful feedback when someone complained that he hadn't asked the question the right way. This led to a long series of messages about the right way to ask the question, dragging along more and more acrimonious accusations that the complainer was not being nice to newbies. This exchange, involving a lot of correspondents, created so many irrelevant messages on the thread that I had to be careful in interpreting results to avoid letting it skew them.
There is no doubt that the exchange was distracting and wasteful. The person who posted the original message took up time reading the exchange; I know this because he threw in his own opinions a few times and tried to justify the way he had asked his question.
Incidentally, this was one of the resolved threads—that is, despite the noise on the thread, the answer to the technical question eventually came. I thought the original correspondent would be scared away forever, but in fact he was back the very next day with another question. In one sense this is good: he stuck with Linux and with the list. But in another sense it's a bad result, because it shows he had not learned enough about his system to solve his problems by himself. I will explore the question of reader education in the conclusion to this article.
A key goal of any mailing list should be to wean users from dependence on the list to solve their technical needs. New users need help to find information, and even experts are sometimes stumped, but every user should find himself or herself using the list sparingly and should strive to become adept at solving problems without help. Another way to frame this goal is that users should evolve from questioners to respondents. This philosophy highlights the value of pointing list members to outside sources of information.
Most of the 28 questions I recorded were specific and detailed enough to show that questioners had worked quite a bit before resorting to the list, and had made good-faith efforts to find information on their own. Even so, one assumes that many questions are answered in release notes, bug reports, project web pages, and other places that may be hard to find. Therefore, one would expect answers to point to outside documentation.
A simple check for references to URLs, as well as to books and to traditional Unix documentation such as manpages and info pages, shows that a modest amount of referencing occurs:
This is a decent number of references for a sample of 28 threads.
These are traditionally found on the computer system along with the software they document. The disparity between references to URLs and references to this offline documentation shows that documentation is moving online, where it can be updated dynamically. As evidence of this trend, manpages and info pages can usually now be found online as well as on the local computer system.
This result gave me pause as a book editor in the Linux space. I was not surprised by it, though, because in several years of sampling the Linux-related lists I have never seen anyone recommend a book. Once or twice a questioner explicitly requested advice on what book to get, and received one or two replies. But there seems to be a macho attitude in the Linux community toward solving problems through experimentation and consultation of quick-reference material. On other lists, I've seen many more recommendations for books.
The mere presence of references does not mean that the references are useful. But they show that mailing lists are part of a larger learning environment, and to some extent the members recognize that. However, interaction with external references is very limited. People who post references do not generally help the readers understand what to look for in the documents or how they apply. I will expand on this point in the conclusion.
Mailing lists can be expeditious sources of information and can build community. But the research behind this article suggests that mailing lists fall short sometimes, and involve some inherent inefficiencies even when they succeed in providing answers.
When someone comes to a mailing list, there are three possible causes—three types of information failure:
The information has not been written anywhere. This is a common problem, despite the vast amount of written computer documentation. There are many subtleties in complex software that have gone unexplained. Information may also be missing for bugs or quirks in newly released software.
The information has been written, but it is prohibitively hard to find. This happens because web searches are not perfect, and few projects provide well-organized collections of pointers to the relevant information stored in idiosyncratic places.
The information has been written and can be found, but the user does not know how to find it. This is part of the larger education problem I have been discussing.
In the common case where someone is entering a command with the wrong options, and someone provides the right ones, one might classify this as the third type of information failure. After all, the questioner had access to the documentation but misinterpreted it.
I'd like to reframe the viewpoint, though. If someone misinterpreted documentation, he lacked the background knowledge to understand it. I think this is a failure of the first type. What he needs is background documentation that helps him place the command and options in the context of his needs. This is the hardest type of documentation to produce, because mere academic descriptions of systems offer little to most users.
The need for background is hard to explain to computer users, and hard to define as a goal. My greatest concern is that mailing lists provide answers too quickly and too easily. Ideally the questioner is guided toward a broader and deeper understanding of her system, but often she is just told what to do to solve her problem with no breadth or depth. She has been given a fish for today, but tomorrow she may find herself marooned without a sinker on her hook.
On the other hand, the solution should not involve requiring every user to read thousands of pages of background documentation before touching the system. We need to find a path that combines John Dewey's classic doctrine of "learning by doing" with techniques for building mental models that guide users to solving their problems. Community support through mailing lists and IRC channels can certainly play a role. But we don't yet know how this works, and it probably works differently for every individual. If researchers can find ready techniques for guiding new users—and if people posting to mailing lists can adopt them—mailing lists could accomplish a lot more than they do now.
First, list members could work harder to investigate the questioner's problem. Certainly, this is hard to do when they are at remote locations. It would be interesting to experiment with the use of remote login to let experts look at a malfunctioning computer system. Trust would have to be pretty high for this to work, though. A more feasible solution that is often seen on mailing lists is for experts to suggest commands to enter and symptoms to look for. If this could be formalized into a troubleshooting procedure linked to common symptoms, future users could benefit.
Furthermore, experts could give new users not only pointers to documentation, but guidelines for what to look for. Reading technical documents is a skill that grows with technical knowledge
So a mailing list can play a role in filling a gap between the documentation and the user's understanding. But list members should understand the importance of providing this bridge. Mailing lists must be seen as part of an information ecosystem in which they are one of the most supple and fastest-moving creatures.
The data for this study is available in the form of the original mail messages (a gzipped tar file) and results of database queries.

This work is licensed under a Creative Commons Attribution 4.0 International License.